The Nature of Computing Innovation
What constitutes our technologies, and how do they evolve?
January 21, 2025
In his book The Nature of Technology, W. Brian Arthur describes technology as combinations of other technologies. This description poses a couple of questions for computing.
First, take a software program like Git. To figure out what technologies Git is made of, perhaps all we have to do is inspect its dependencies? Surprisingly, Git has few real dependencies.¹
Second, note how Arthur’s description of technology is recursive — where does it end? His answer is in elemental technologies. These are technologies which deliver an effect based on a natural phenomenon:
That certain objects — pendulums or quartz crystals — oscillate at a steady given frequency is a phenomenon. Using this phenomenon for time keeping constitutes a principle, and yields from this a clock.— W. Brian Arthur, The Nature of Technology
If we re-examine Git not by its software dependencies, but by the algorithms and data structures in its source, we get closer.²
Consider Git’s recursive three-way merge feature:
- Recursive three-way merge is built from Diff3 and a DAG of commits;
- Commit objects associate metadata with a top-level tree;
- Tree objects are directory-like structures which associate filenames with sub-trees and hashes;
- Hashes are SHA-1 hashes of blobs;
- Blobs consist of a header string and DEFLATE-compressed binary data.
The Huntley-Mcllroy diff algorithm operates on the phenomenon that ordered correspondence survives editing. Myers diff improves the performance by exploiting the the fact that text changes are sparse. Diff3 can reconcile texts to a common ancestor because independent edits to separate regions are commutative.
In other words:
A technology is a programming of phenomena to our purposes.— W. Brian Arthur, The Nature of Technology
A Dependency Diagram
We can model Git’s merging ability as dependency diagram:
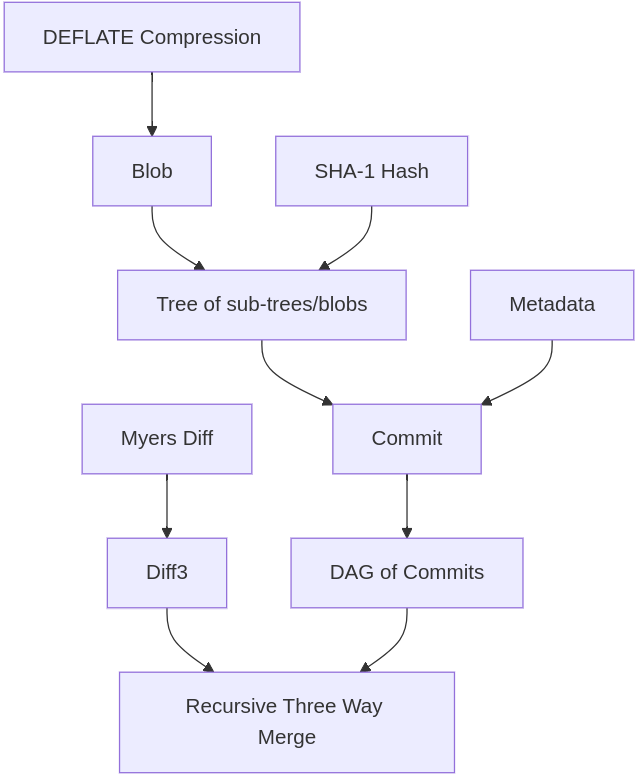
In this diagram, rounded rectangles are phenomena, rectangles are algorithms, and cylinders are data structures.
Note the hierarchy: the arrows indicate (approximate) “using” relationships. Git’s recursive three-way merge uses a version of Diff3 that uses Myers’ difference algorithm.³
Innovation’s frontier
Git’s speed, correctness guarantees and efficient use of space were essential to its success.⁴ Without the availability of suitable technologies, “Git” would have been beyond the technology frontier.
Zooming out from Git, imagine that we have modeled all computing technologies on a giant dependency diagram. The frontier of computing innovation then, is defined as the set of all possible combinations of nodes in the diagram.
The Dependency Diagram can also help us define terms:
- Invention is the discovery of a new phenomenon and an algorithm and/or data structure to harness it. A new root node is added.
- Innovation is a novel combination of existing nodes to accomplish a new effect; new child nodes are added.
- Engineering is the software development we do every day. Creating apps, fixing bugs etc. These create or modify child nodes, but they’re unlikely to have descendants.
In terms of the number of descendants: invention > innovation > engineering. This is why the dictionary (hashed binary tree of pairs) is an important data structure, but the config struct for any particular app is not.
Disruption
What would it take to displace Git? Discovering a better algorithm that uses the same data structures wouldn’t be enough as Git itself could adopt it. For example, Git now defaults to using SHA-256 instead of SHA-1.
It seems like disruption would require an innovation that created a fundamentally better way of version control. Such as using a schema-aware difference algorithm. If no such technologies exist yet, disruption is beyond the frontier.
But that’s not all:
I am struck that innovation emerges when people are faced by problems — particular, well-specified problems.— W. Brian Arthur, The Nature of Technology
Returning to our imaginary Dependency Diagram of all computing technologies, we might say the number of possible combinations of nodes is too costly to search. Well-specified problems are helpful because they constrain the search space.
When Larry McVoy created BitKeeper he invented the concept of distributed version control. Later when he stopped providing BitKeeper to the Linux kernel project for free, he created a problem which actually spawned two new version control systems: Mercurial and Git.⁵
We can model the effects of disruption using the Dependency Diagram; the disrupted technology and its descendant nodes will be discarded in favor of a new hierarchy of nodes. As the new technology evolves,⁶ its changing components contribute more nodes to the diagram. The effects of those changes ripple out, driving further adaptations and disruptions.
Arthur calls this destruction an “avalanche”. BitKeeper was swept away, but the technologies it used were spared.⁷ Meanwhile Git and the web enabled new technologies like GitHub.
- E.G. in Git 2.47.1 many dependencies are optional.
- Git Internals - Git Objects describes some of these.
- Git uses the linear space variant, which occasionally makes for some weird diffs.
- Linus explained this in an early talk at Google. Git was so much faster than the rest that it changed how users actually did version control. A large change in speed becomes a change in kind.
- The coincidence of pejoratives as project names is striking.
- Arthur describes several forces which drive adaptations in existing technologies: internal replacement, lock-in and adaptive stretch and structural deepening.
- Rochkind’s Source Code Control System (the original version control system for Unix) interleaves all versions of a file into a single structure called interleaved deltas (or the “weave”). BitKeeper uses a weave-merge algorithm.